Insights · Article · Data & AI · May 2026
Point-in-time correctness, schema evolution, null semantics, and monitoring joins that catch silent skew before models silently rank the wrong customers.

A centralized feature store promises a single definition of truth shared across offline training and real-time online serving. Every feature gets computed once, versioned explicitly, and consumed identically whether a batch pipeline is replaying three years of history or a scoring endpoint is evaluating a customer in under fifty milliseconds. That architectural guarantee is the reason platform teams invest months standing up the infrastructure in the first place.
Operational reality erodes that guarantee faster than most organizations expect. Late-arriving event streams, retroactive financial backfills that rewrite ledger history, and schema changes pushed without version bumps all introduce divergence between what a model trained on and what it sees at inference time. The insidious quality of feature store drift is that nothing crashes; the system continues serving predictions, just quietly wrong ones.
The earliest symptom is almost never a dramatic accuracy collapse. Instead, teams notice that null values are interpreted differently across languages, that timestamps were truncated to UTC midnight during a migration, or that a categorical encoding silently shifted when an upstream ETL job was redeployed. Each of these issues looks minor in isolation, yet their compound effect can skew model outputs by double-digit percentages for specific customer segments.
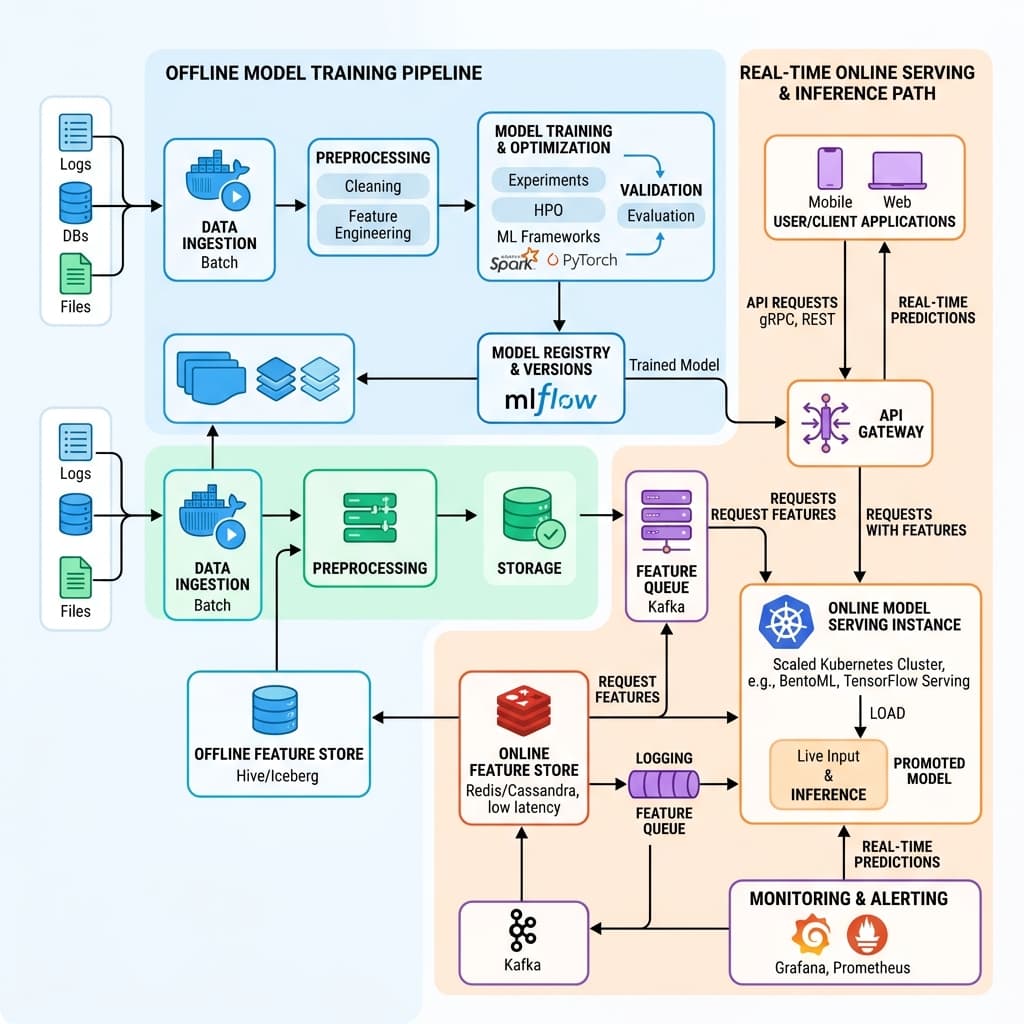
Point-in-time joins represent the moral center of any predictive ML system. When constructing a training dataset, each row must reflect only the information that was actually available at the moment a decision was made. If the join logic accidentally peeks at future data, the resulting uplift charts will look impressive in a slide deck while completely misrepresenting what the model can achieve in production.
Data leakage through incorrect temporal joins is notoriously difficult to detect after the fact. Standard evaluation metrics such as AUC or precision at threshold may remain high because the leaked signal is genuinely predictive. The only reliable defense is an automated replay framework that reconstructs features from raw event logs and compares them against what the training pipeline actually materialized at each historical timestamp.
We facilitate small-group sessions for customers and prospects without requiring a slide deck, focused on your stack, constraints, and the decisions you need to make next.
Schema evolution introduces a second class of drift that is entirely structural rather than statistical. A column that once held integer category codes may be widened to accept strings, or a nested array may be added to a previously flat record. Without forward-compatible readers and explicit default policies, downstream consumers will silently interpret the new shape using the old logic, producing features that parse without error yet carry the wrong meaning.
Default fill policies deserve particular scrutiny. Many frameworks substitute zero for missing numeric fields, which is harmless for additive counters but catastrophic for ratio features or indicators where zero carries a specific semantic meaning. A missing credit utilization ratio is fundamentally different from a zero utilization ratio, and conflating the two can invert the risk signal an underwriting model relies on.
Null propagation across join keys compounds the problem further. When a left join fails to find a match, the resulting null may be coerced to a framework-specific sentinel value that varies between Spark, Pandas, and the online serving library. Feature store teams should enforce a single canonical null representation and validate it with contract tests that run on every code path, both batch and streaming.
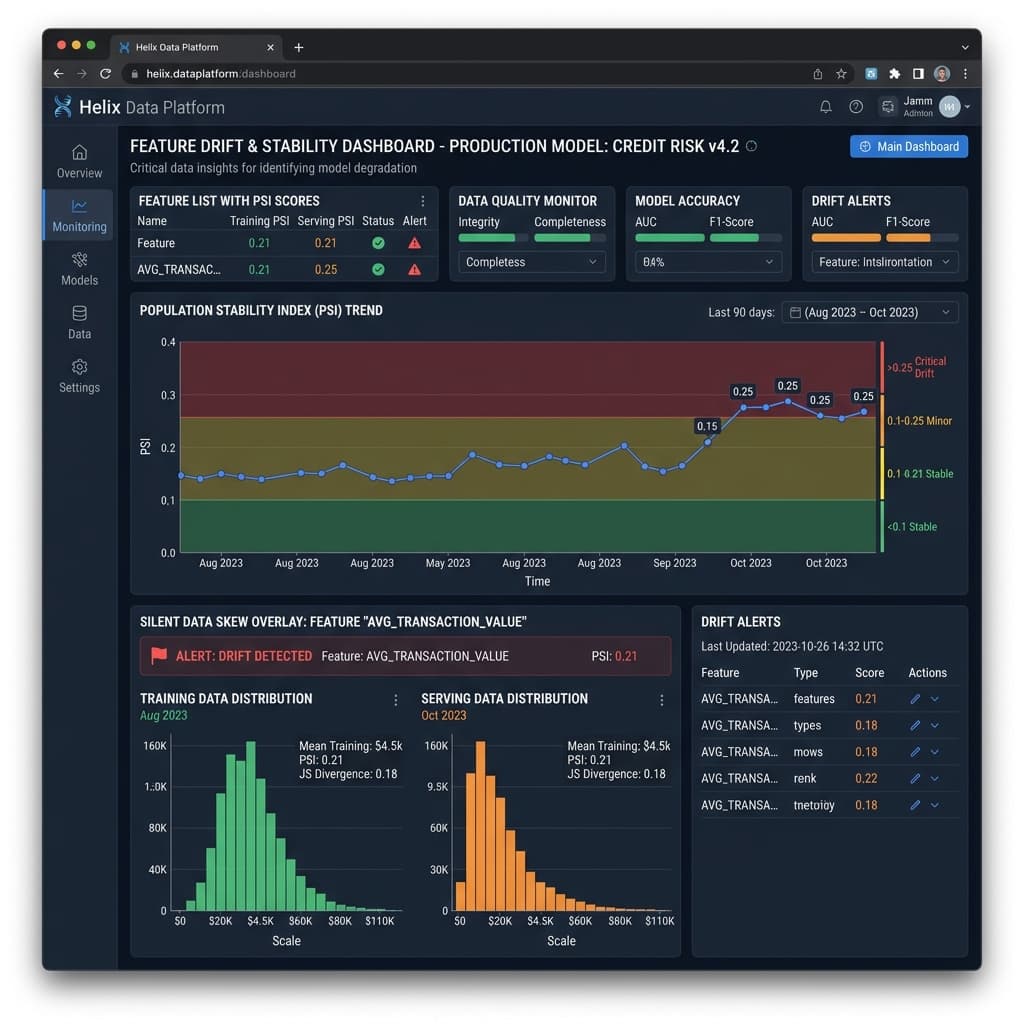
Monitoring feature drift effectively requires separating data quality checks from model performance checks. Data quality asks whether the features themselves still look correct: are distributions stable, are null rates within tolerance, do cardinality counts match expectations? Model performance asks a different question entirely: given correct features, is the learned relationship between inputs and outputs still valid? Conflating the two delays root-cause analysis.
Population stability index and Kolmogorov-Smirnov tests provide useful distributional baselines, but they must be applied at the segment level, not just in aggregate. A global AUC can look perfectly stable while a protected demographic subgroup drifts significantly because external base rates shifted or because a policy change altered the composition of the incoming population. Segment-level monitoring turns vague alerts into actionable investigations.
Alert fatigue is one of the most practical obstacles to effective drift monitoring. If every minor fluctuation fires a page, engineers learn to ignore the dashboard entirely. Tiered alerting helps: informational notices for slow statistical shifts, warnings when a population stability index breaches a defined threshold, and critical pages reserved for schema violations or null rate spikes that indicate a broken pipeline rather than organic change.
Ownership of feature definitions should sit with the domain teams who understand the business meaning of each variable, not with a centralized platform group that merely hosts the storage layer. A fraud analytics team knows that transaction velocity should be computed over a rolling seven-day window, while a marketing team may need the same underlying events aggregated hourly. Platform teams provide tooling and governance; domain teams own correctness.
That ownership model requires clear contracts. Each feature should carry metadata that specifies its expected type, permitted null rate, valid value range, freshness SLA, and the owning team contact. When a contract violation is detected, the monitoring system should route the alert directly to the responsible domain team rather than funneling everything through a shared on-call rotation that lacks context to triage effectively.
Periodic reconciliation jobs are the unglamorous practice that catches the bugs statistical monitoring misses. These jobs sample a set of entity keys, recompute their features from raw event logs using the offline pipeline, and compare the results against what the online serving layer actually returned during the same time window. Discrepancies reveal encoding mismatches, timezone handling errors, and caching staleness that no amount of distributional testing alone would surface.
Integration testing for feature pipelines should run against a realistic shadow environment rather than synthetic fixtures. Real data carries edge cases that generated test data rarely reproduces: unicode in name fields, negative transaction amounts from chargebacks, timestamps in nonstandard zones. Shadow replay tests that process a recent slice of production traffic provide the highest confidence that offline and online paths remain aligned.
Organizational maturity in feature store operations tends to follow a predictable arc. Teams start by centralizing storage, then discover they need versioning, then learn that versioning without monitoring is insufficient, and finally arrive at the conclusion that monitoring without clear ownership is just noise. The feature store is not a database; it is a living contract between the teams that produce data and the models that consume it. Treating it as such is what separates resilient ML platforms from brittle ones.


