Insights · Article · Engineering · Apr 2026
Governance for flag lifecycles, kill switches in regulated domains, and telemetry that proves canaries before you widen blast radius.

Feature flags allow engineering teams to decouple deployment from release, giving product organizations the ability to ship code to production without immediately exposing new behavior to every user. This separation accelerates learning cycles, enables controlled experimentation, and reduces the risk inherent in large coordinated launches. For startups running a single service, a simple environment variable might suffice. At enterprise scale, however, the calculus changes entirely.
When hundreds of engineers across dozens of teams maintain thousands of flags simultaneously, those toggles can quickly accumulate into unmanageable configuration debt. Stale flags bloat codebases, create hidden coupling between services, and introduce compliance hazards in regulated industries. Without deliberate lifecycle management, the very mechanism designed to reduce risk becomes a source of fragility, inconsistent user experiences, and audit failures that are expensive to remediate after the fact.
Governance is the foundation that prevents flag sprawl from undermining delivery velocity. It begins with a clear taxonomy: release flags for gradual rollouts, experiment flags for A/B tests, operational flags for circuit breakers, and permission flags for entitlement gating. Each category carries different expectations for lifespan, ownership, and review rigor. Mixing them into a single undifferentiated list makes it nearly impossible to prioritize cleanup or assess organizational risk accurately.
Every active flag should have a named owner, a documented purpose, and an enforced sunset date. Ownership transfers when engineers change teams; orphaned flags with no accountable owner must be escalated to engineering leadership within a defined SLA. Permanent infrastructure toggles, such as those controlling database routing or regional failover behavior, represent long-lived configuration rather than temporary experiments. These belong in restricted administrative tooling governed by formal change management processes.
Naming conventions deserve more attention than most teams give them. A prefix scheme that encodes the flag category, owning team, and creation quarter makes it trivial to query for stale flags programmatically. For example, a convention like rel.payments.2026q1.checkout-redesign immediately communicates the flag type, domain, vintage, and feature scope. Automated linting rules can then enforce the convention at creation time, preventing ad hoc names that resist future discovery.
We facilitate small-group sessions for customers and prospects without requiring a slide deck, focused on your stack, constraints, and the decisions you need to make next.
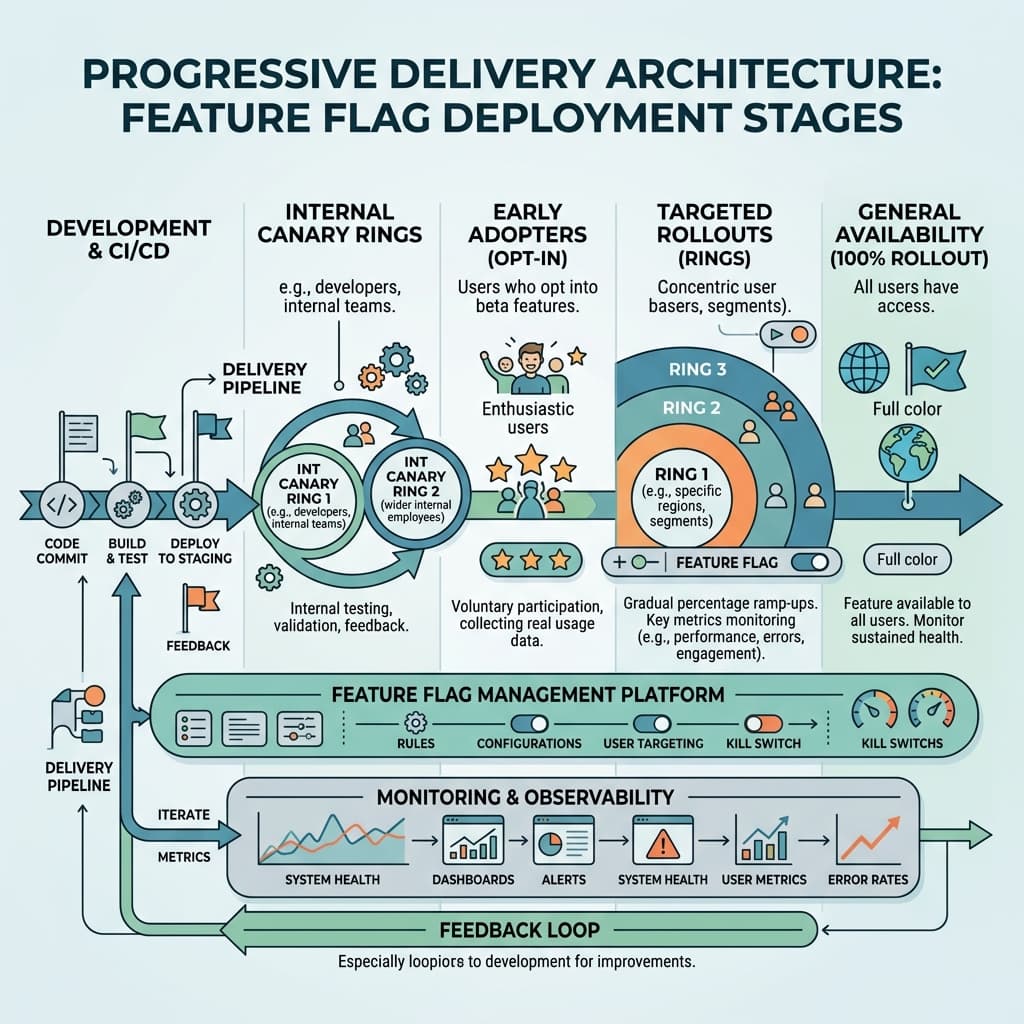
Progressive delivery extends feature flags beyond binary on-off states into a staged rollout discipline. A typical pipeline starts with an internal dogfood ring, expands to a small percentage canary cohort, widens through graduated percentage ramps, and finally reaches general availability. Each stage gate should be paired with automated health checks that evaluate error rates, latency percentiles, and business metrics before the system advances exposure to the next tier.
This staged approach only works when observability infrastructure can segment telemetry by flag state. If your monitoring dashboards cannot isolate the latency profile, error volume, and conversion rate of users who received the new code path versus those on the control, you are flying blind. Cohort-aware observability is not optional; it is the mechanism that transforms progressive delivery from a theoretical framework into a practical safety net.
Invest in deterministic request tagging early. Propagate the evaluated flag state as a structured header through every downstream service call, and configure your distributed tracing system to index on those values. This allows engineers to filter traces, logs, and metric dashboards by exact flag combination. When an anomaly surfaces, the team can pinpoint whether the regression correlates with the new feature path or with an unrelated environmental factor within minutes rather than hours.
Sampling strategy matters at scale. Tracing every request at full fidelity is cost-prohibitive for high-throughput services. Instead, implement adaptive sampling that increases capture rates for flagged cohorts during active rollouts and tapers back to baseline once a flag reaches general availability. This ensures you have statistically significant trace data precisely when you need it most, without inflating observability costs during steady-state operations.
Regulated industries introduce additional constraints that generic feature flag platforms rarely address out of the box. In financial services, healthcare, and government technology, every configuration change that can alter user-facing behavior may fall under audit and compliance scrutiny. Flag mutations must generate immutable audit records that capture who approved the change, when the approval occurred, and the precise before-and-after state of the flag definition.
Separation of duties is a core compliance control. The engineer who authors a flag change should not be the same individual who approves its activation in production. Many organizations implement a two-person rule: one engineer proposes the rollout plan, and a second engineer or release manager reviews the telemetry criteria and authorizes the percentage increase. Emergency kill switches bypass this flow by design, but each invocation must trigger a formal post-incident review within a defined window.

Where flags are evaluated, client side or server side, has significant security and competitive implications. Client-side evaluation ships flag rules and targeting data to the browser or mobile device, where any technically curious user can inspect the payload. Treat every client-side flag bundle as public information. Sensitive experiments, such as unreleased pricing tiers, acquisition funnel variations, or competitive feature previews, should never appear in client-evaluated configurations.
Server-side evaluation keeps targeting logic and flag metadata within your own infrastructure. The client receives only the resolved boolean or variant value, revealing nothing about the underlying rules. This approach is essential for protecting launch timelines, pricing strategies, and partnership features from premature disclosure. The trade-off is added latency for the initial evaluation call, which can be mitigated through edge caching, sticky sessions, or bootstrapping flag values during server-side rendering.
Testing strategy must account for the combinatorial reality of multiple concurrent flags. When ten flags are active simultaneously, the theoretical state space exceeds one thousand combinations. Exhaustive coverage is impractical, so quality engineering teams must adopt a risk-based prioritization approach. Identify which flag intersections touch shared code paths, data pipelines, or critical user journeys, and concentrate automated test coverage on those high-risk pairings.
Contract tests are particularly effective here. Rather than spinning up full integration environments for every flag combination, define behavioral contracts for each feature path and verify them in isolation. Continuous integration pipelines should evaluate a curated matrix of flag states on every pull request, catching regressions before they reach production. Flag-aware test fixtures that deterministically set flag values simplify authoring and improve reproducibility across local and CI environments.
Developer experience is the silent determinant of whether a progressive delivery platform succeeds or fails. If creating a new flag requires navigating three dashboards, writing boilerplate configuration, and waiting for a deployment cycle, engineers will bypass the system entirely. Fast command-line tooling, sensible library defaults, and local development overrides that let engineers toggle flags without network calls reduce friction to the point where using the platform becomes the path of least resistance.
Internal platform teams should publish opinionated SDK wrappers for every language in the organization's stack. These wrappers should handle initialization, caching, fallback behavior, and telemetry integration out of the box. Golden path documentation with copy-paste examples for common patterns, such as percentage rollouts, user-segment targeting, and mutual exclusion groups, lowers the barrier to adoption and ensures consistent implementation across teams that may have limited feature flag experience.
Vendor portability deserves deliberate architectural investment. The feature flag market is competitive and evolving rapidly; the platform you select today may not be the best fit in three years. Abstract your flag evaluation behind a thin internal interface so that application code never depends directly on a vendor SDK. This indirection layer also provides a natural integration point for audit logging, metrics emission, and default-value policies that remain consistent regardless of the underlying provider.
Export flag metadata, targeting rules, and historical evaluation data on a regular cadence. Store these exports in a durable, queryable format that your governance tooling can reference independently of the vendor platform. When a migration eventually occurs, this archive ensures that audit trails, sunset schedules, and ownership records survive the transition intact, sparing your organization the painful archaeology of reconstructing flag history from scattered pull requests and Slack threads.


