Insights · Article · Strategy · May 2026
Buddy systems, access automation, first deploy milestones, and knowledge bases that stay accurate when teams rename every six months.

Static onboarding documents rot faster than source code because corporate reorganizations rename chat channels, reassign infrastructure ownership files, and scramble escalation paths on a quarterly basis. Engineering teams that hardcode playbooks around specific group names create permanent knowledge traps for confused new hires. The result is a frustrating first week where every hyperlink leads to an archived Slack channel and every wiki page references a manager who left months ago.
This structural decay is not a documentation failure; it is an architectural one. Onboarding content that couples tightly to organizational topology inherits the same volatility as the org chart itself. When leadership decides to merge the platform reliability group into the cloud infrastructure team, dozens of onboarding references silently break overnight. New engineers absorb outdated context without realizing it, and the damage compounds across every subsequent hire until someone flags the drift.
The most resilient engineering organizations treat onboarding playbooks as living systems rather than static artifacts. They version control their content, assign explicit owners, and run automated checks that detect broken internal links. This deliberate investment in onboarding durability pays compound dividends because every engineer who ramps up a week faster is a week of additional productive output that scales across your entire annual hiring plan.
Platform teams should strategically anchor onboarding journeys to immutable underlying systems and core operational flows rather than team names. Documenting how to ship a validated change safely, how to page networking infrastructure, and where to locate customer impact dashboards survives leadership renames far better than any organizational chart. When content references a service rather than a squad, a repository rather than a Slack channel, it remains accurate through multiple reorganization cycles.
Mapping onboarding milestones to technical capabilities also gives new engineers transferable mental models. Instead of learning that the payments squad owns the billing pipeline, they learn how the billing pipeline works, who is on call for it today, and where its runbooks live. This subtle reframing means the knowledge remains useful even when the squad is dissolved and its responsibilities are redistributed across two newly created teams after the next planning cycle.
We facilitate small-group sessions for customers and prospects without requiring a slide deck, focused on your stack, constraints, and the decisions you need to make next.
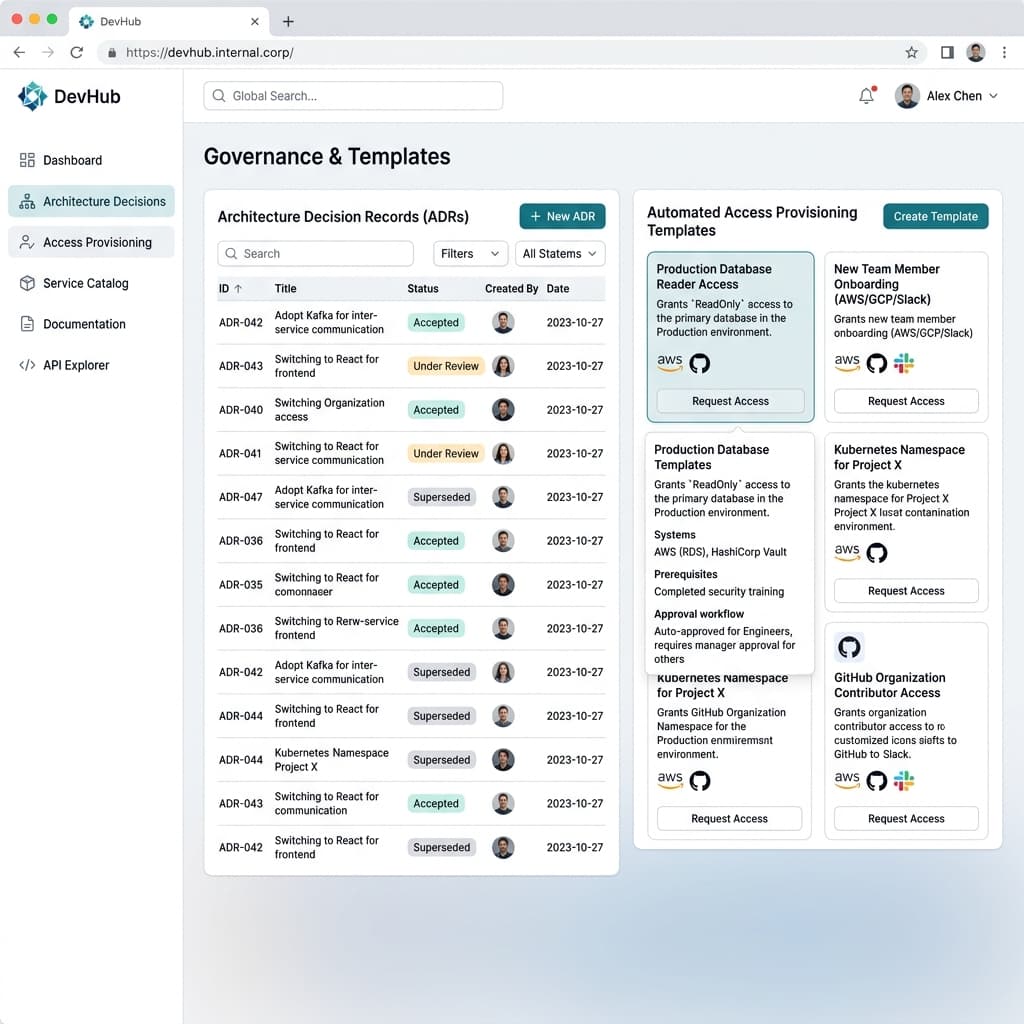
Identity and access provisioning must follow structured role templates integrated directly with human resources data. When manual IT ticketing chains take two full weeks to provision simple repository access, they silently teach every new hire that organizational security is optional bureaucratic friction meant to be bypassed. Automated provisioning tied to role definitions eliminates this corrosive first impression while simultaneously reducing the administrative burden on already stretched security operations teams.
Role templates should be granular enough to distinguish between a backend services engineer and a data platform engineer, yet flexible enough to accommodate lateral moves. A well-designed access matrix maps each role to the minimum set of repositories, dashboards, secrets vaults, and deployment pipelines required on day one. Periodic audits then reconcile the template against actual usage, pruning permissions that accumulate like sediment after successive reorganizations reshape team boundaries.
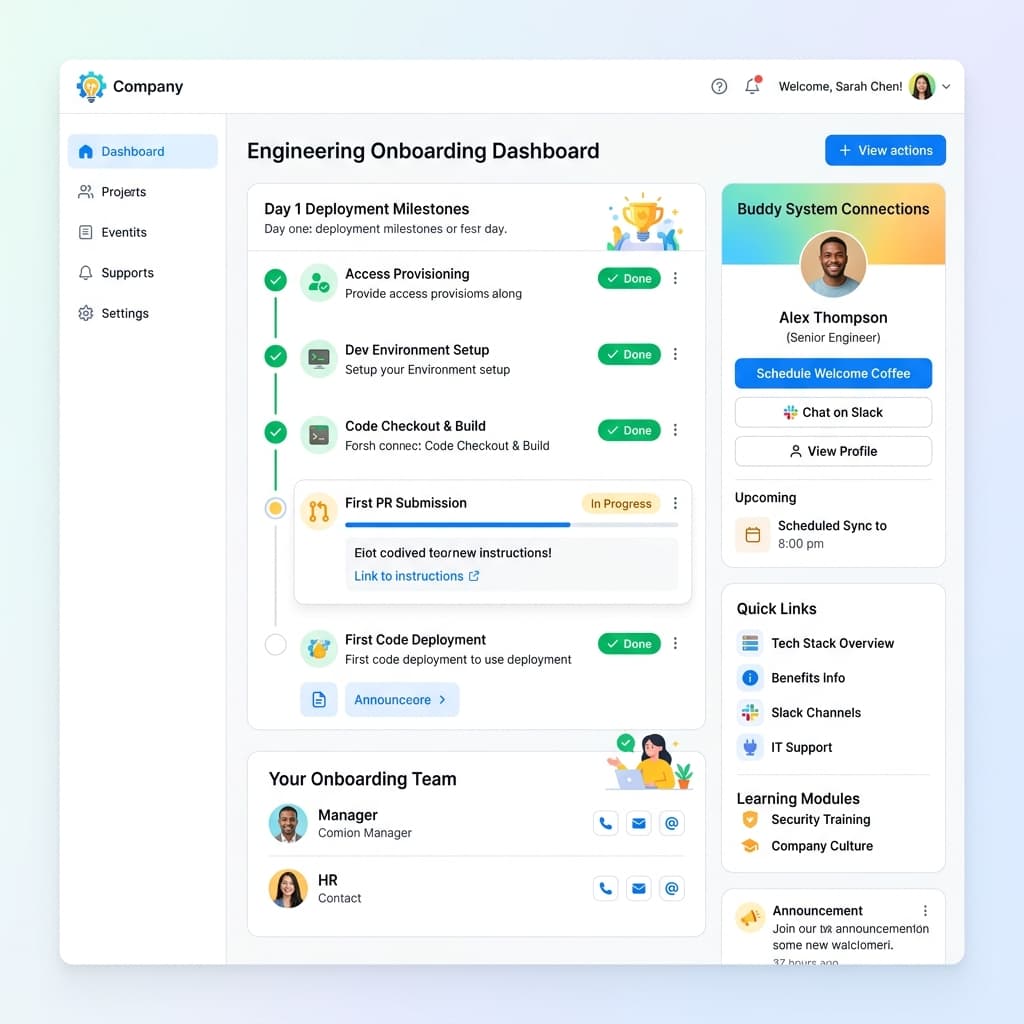
Structured peer buddy assignments require protected engineering capacity above all else. If every senior technical lead is desperately triple booked across sprint commitments, incident response, and hiring panels, the resulting onboarding experience collapses predictably into a series of rescheduled calendar invites. Engineering managers should protect designated mentoring hours with the same rigor they apply to tier one sprint deliverables, because losing a new hire to poor onboarding is far more expensive than slipping a feature by one sprint.
Effective buddy programs also benefit from lightweight structure. A shared checklist of topics to cover during the first two weeks, a standing thirty-minute daily sync, and a clear escalation path for questions the buddy cannot answer prevent the relationship from drifting into awkward small talk. Rotating buddy assignments across senior and mid-level engineers distributes institutional knowledge more broadly and prevents onboarding expertise from concentrating in a single bottleneck individual.
Executing a successful first production deployment within the initial two weeks consistently predicts long-term technical retention better than any corporate swag package. Scope incredibly small, safe configuration changes and pair them with an empathetic code review process that explicitly teaches your fundamental engineering norms. The psychological impact of seeing your commit reach real users within days of joining a company cannot be overstated; it transforms abstract orientation content into tangible professional confidence.
To make early deployments safe, invest in staging environments that mirror production with high fidelity and feature flags that limit blast radius. Provide a curated list of starter tasks labeled specifically for new engineers, each pre-vetted by a tech lead to confirm that the worst possible outcome is a harmless no-op. This preparation requires upfront effort from senior staff, but the return is a pipeline of confident, shipping engineers rather than hesitant observers still reading wiki pages in week three.
Document exactly where critical technical decisions live within the organization. Architecture decision records, unified service catalogs, and published service level objective pages must be centrally discoverable through a single internal developer portal. Fresh engineering hires should never be forced to reconstruct your internal tribal geography by accident, piecing together context from stale Confluence pages, pinned Slack messages, and whispered hallway conversations with tenured staff members.
A robust internal developer portal serves as the canonical entry point for every service your organization operates. Each service page should include an ownership reference that updates automatically from a source of truth such as a CODEOWNERS file or a service registry API. When a reorganization reassigns ownership, the portal reflects the change within hours rather than months, and onboarding content that links to the portal inherits this accuracy for free.
Cognitive diversity and inclusive operating structures belong at the center of your onboarding curriculum design, not as an afterthought appended to the final slide deck. Explicitly stating team meeting norms, standardizing asynchronous communication etiquette, and providing written agendas before every synchronous session measurably reduces psychological anxiety for new hires. These practices also improve overall code review quality because engineers feel safe asking clarifying questions instead of silently approving changes they do not fully understand.
Platform teams should programmatically measure the total elapsed time to the tenth meaningful commit, track the duration until the first on-call shadow rotation, and collect survey sentiment scores at the thirty-day milestone. These metric trends reveal systemic architectural friction that individual junior engineers cannot fix alone. Dashboards that surface these numbers to engineering leadership create accountability and make it impossible to ignore a deteriorating onboarding experience quarter after quarter.
Segment your onboarding metrics by team, office location, and seniority level to surface hidden disparities. A median time-to-first-deploy of five days across the organization may mask the fact that remote hires in a different time zone take twelve days because their buddy is never online during overlapping hours. Granular data turns vague complaints into actionable improvement tickets that platform teams can prioritize alongside their regular infrastructure roadmap.
Finally, engineering leadership must rigorously refresh central playbooks immediately following each major reorganization as an enforced checklist item, not a suggested best practice. Assign a directly responsible individual for each onboarding module, set a seventy-two-hour deadline for updates after any structural change, and block the reorganization announcement from going live until the onboarding audit is complete. Treat the entire onboarding process like a critical database migration, not an optional wiki page edit.


