Insights · Article · Cloud · Apr 2026
Store gateways, sorting facilities, and moving fleets: how to keep workloads fast, offline tolerant, and observable from a central SRE function.

Deploying edge computing infrastructure within retail environments and distributed logistics fleets demands predictable system behavior when wide area network links degrade. Strong reference patterns must clearly dictate which computational decisions execute locally, which analytics can wait for delayed cloud synchronization, and how engineering teams detect split brain data scenarios before they trigger inventory allocation chaos. Without disciplined architecture, the edge quickly becomes a patchwork of fragile workarounds that collapse under peak holiday traffic.
The core challenge is that retail and logistics edge sites differ wildly in physical capability, connectivity quality, and operational staffing. A flagship urban store with fiber uplinks bears little resemblance to a rural distribution center relying on a single cellular modem. Reference patterns must therefore be parameterized rather than monolithic, defining a small set of site profiles that map cleanly to deployment templates, networking policies, and failover strategies tailored to real world conditions.
Enterprise architects approaching this space should resist the urge to replicate full cloud native stacks at every site. The goal is selective computation: running only what must be local for latency, compliance, or resilience reasons, while deferring everything else to centralized services. This principle keeps edge footprints small, reduces patching surface area, and limits the blast radius when a single location experiences hardware failure or a security incident that requires rapid containment.
Engineering teams should begin with rigorous workload classification. Point of sale transaction resilience, barcode scanning latency, and physical safety telemetry on the warehouse floor carry entirely different compliance mandates. Each functional class needs explicit non-functional requirements that centralized architects can test through automated chaos engineering. Classification also informs hardware sizing: lightweight transaction caching needs far less compute than on-site machine learning inference for package sorting optimization.
A mature classification framework groups workloads into three tiers. The first tier covers safety critical and revenue critical functions that must complete locally within milliseconds regardless of upstream connectivity. The second tier includes analytics and reporting tasks that tolerate minutes of delay but still require eventual consistency guarantees. The third tier captures background synchronization, software updates, and telemetry uploads that can gracefully queue for hours without user visible impact.
We facilitate small-group sessions for customers and prospects without requiring a slide deck, focused on your stack, constraints, and the decisions you need to make next.
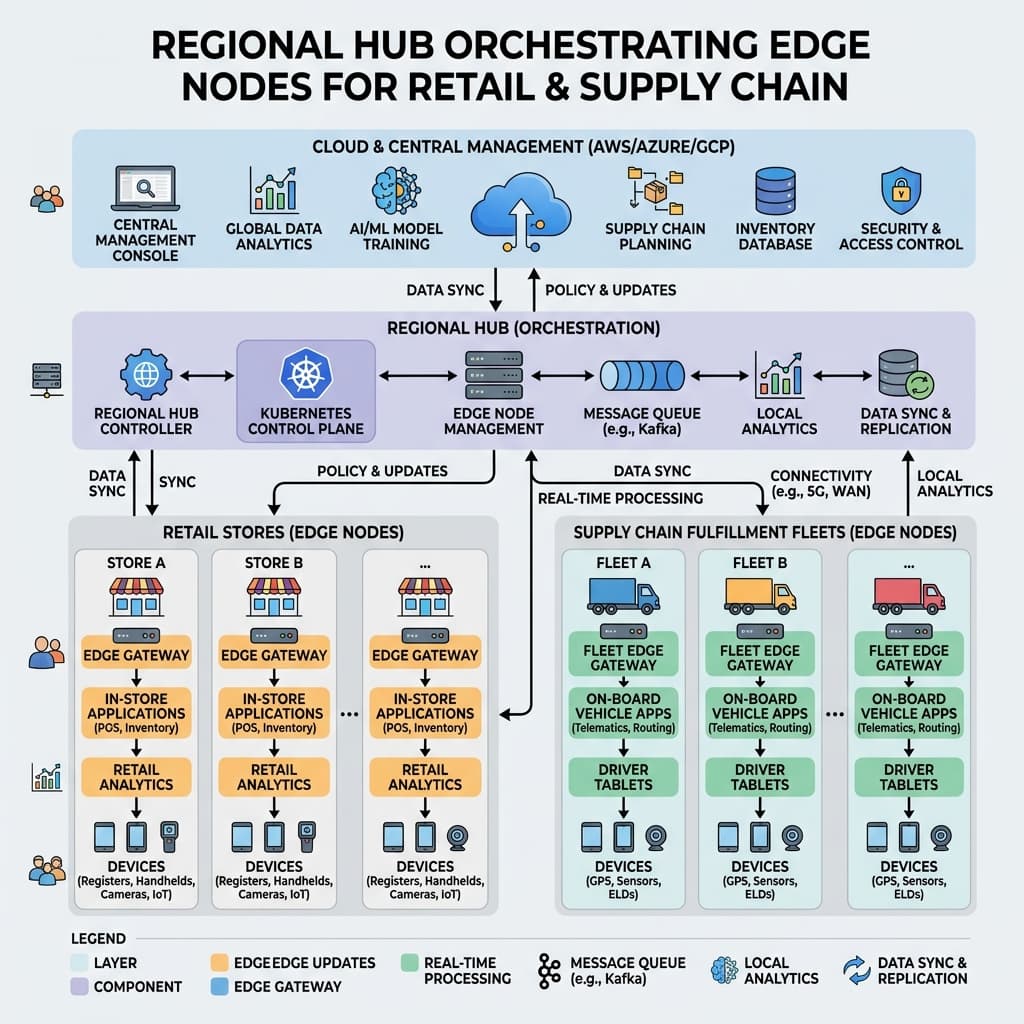
The hub and spoke topology illustrated above offers a practical middle ground between full autonomy at each site and total dependence on a distant cloud region. Regional hubs aggregate telemetry, distribute configuration updates, and serve as warm failover targets for neighboring edge nodes. This layered model means a cloud region outage affects reporting dashboards but never halts checkout lanes or conveyor belt sorting logic operating at the physical edge.
Running containerized microservices at the tactical edge remains attractive but demands disciplined release engineering. Golden container images, cryptographically signed deployment bundles, and staged rollout pipelines matter substantially more when an enterprise cannot debug one thousand separate store racks overnight. Teams should enforce strict image provenance checks at pull time, rejecting any artifact that lacks a verified signature chain tracing back to the central build system.
Rollout strategies must account for the reality that edge nodes cannot always be reached on demand. A pull-based reconciliation model, where each node periodically checks for new desired state and converges independently, proves far more reliable than push-based deployments that assume continuous connectivity. Canary releases should target a representative sample across connectivity profiles and geographic regions before wider promotion to the full fleet.
Resource constraints at the edge also shape container runtime choices. Full Kubernetes clusters may be overkill for a store gateway running three lightweight services. Lighter orchestrators or even simple systemd-managed containers reduce memory overhead and startup time. The key is standardizing the deployment artifact format so that the same signed image runs identically whether scheduled by Kubernetes in a regional hub or by a minimal runtime on a single board computer in a delivery van.
Cryptographic identity management and secrets handling require specialized operational care. Shared service accounts stretched across thousands of devices create massive blast radiuses. Architects should prefer device-bound credentials, short-lived tokens, and centralized revocation paths that function even when half the logistics fleet operates offline. Hardware security modules or trusted platform modules embedded in edge devices add a physical root of trust that purely software-based solutions cannot match.
Zero trust networking principles apply forcefully at the edge. Every service-to-service call should present a verifiable identity, and lateral movement between edge nodes must be blocked by default. Micro-segmentation policies should be defined centrally but enforced locally, ensuring that a compromised store gateway cannot pivot into the regional hub or reach adjacent retail locations. Periodic credential rotation, even for machine identities, closes windows of exposure that static keys leave open indefinitely.

Telemetry and observability pipelines should fan in upstream without drowning wide area network connections. Implement local disk buffering, dynamic sampling rates, and priority channels reserved for safety and revenue impacting signals. Central platform teams need sufficient detail to support rapid incident resolution without shipping every verbose debug log northbound. A well-tuned pipeline reduces bandwidth costs by an order of magnitude while preserving the signals that actually drive alert routing and root cause analysis.
Structured logging conventions deserve special attention in edge deployments. When a central SRE team triages an incident spanning dozens of sites, consistent field names, correlation identifiers, and timestamp formats dramatically accelerate diagnosis. Teams should define a shared logging schema early and enforce it through client libraries rather than relying on downstream parsing heuristics that inevitably drift as new services appear at the edge.
Alerting thresholds must be calibrated for edge realities. A brief connectivity blip at a single store should not page an on-call engineer at two in the morning. Instead, alerts should aggregate across fleet segments and fire only when a statistically significant number of nodes exhibit correlated degradation. This approach filters transient noise while still catching systemic issues like a bad firmware update rolling across an entire geographic region.
Data governance frameworks follow the physical workload. Minimizing sensitive customer personally identifiable information at the edge reduces breach impacts and simplifies cross-border compliance. Security leaders must decide which datasets anonymize locally versus which raw telemetry synchronizes globally for enterprise analytics. Tokenization at the point of capture, replacing card numbers and loyalty identifiers with opaque tokens before any data leaves the store, is rapidly becoming the baseline expectation among privacy regulators worldwide.
Retention policies at the edge also need explicit definition. Local storage is finite, and unbounded log accumulation eventually fills disks, degrading the very services the logs are meant to monitor. Automated rotation policies should prioritize keeping recent high-fidelity data while aging older records into compressed summaries. When connectivity returns after an extended outage, the sync process should transmit these summaries rather than attempting a bulk upload that saturates the restored link.
Platform engineering must test aggressive disaster scenarios including complete regional cloud outages, domain name system failures, lateral ransomware isolating a store controller, and supplier API degradation during peak shopping seasons. These tabletop exercises should include operations managers and external logistics partners. Simulating a holiday weekend with degraded connectivity reveals architectural blind spots that whiteboard reviews consistently miss, making regular game days a non-negotiable practice for any serious edge deployment.
Recovery time objectives should be defined per workload tier. Tier one functions like checkout and package scanning must recover within seconds through local failover, requiring no human intervention. Tier two analytics may tolerate minutes of downtime provided data integrity is preserved for later reconciliation. Tier three background tasks simply resume when conditions improve. Documenting these targets and validating them quarterly through automated fault injection keeps recovery promises credible rather than aspirational.
Fiscally responsible executives should compare heavy capital expenditure for custom on-premise hardware against operational subscription spend for managed edge appliances and cellular connectivity. The optimal answer varies with geographic store counts, depreciation cycles, and whether the enterprise already operates a private networking backbone. Hybrid models, where the retailer owns core compute but leases connectivity and management tooling, increasingly offer the best balance of control, cost predictability, and operational simplicity for mid-market organizations.
Finally, close the feedback loop with an actively maintained architecture decision record repository. Edge computing decisions age quickly as cloud vendors merge new platform features. Maintained records help newly hired engineering leaders understand why a legacy pattern exists and whether its original constraints still apply. Coupling each record with automated fitness functions that validate the decision's assumptions against current telemetry turns static documentation into a living governance mechanism that flags when it is time to revisit a prior choice.


