Insights · Article · Engineering · Apr 2026
OCR, extraction, validation, and human-in-the-loop queues that keep straight-through processing honest when models face messy real-world paperwork.

Commercial banking and insurance providers have promised fully automated document processing for years, yet reality remains far messier than vendor demos suggest. Fax machine shadows, low resolution mobile uploads marred by glare, and handwritten contractual amendments still arrive daily. Modern document intelligence pipelines only succeed when they architecturally embrace physical imperfection and route model uncertainty to specialized human reviewers rather than silently guessing.
The business case for investing in document intelligence is straightforward: loan origination and insurance claims intake are two of the most document intensive workflows in financial services. Each delayed application or misrouted claim translates directly into lost revenue, regulatory risk, and customer dissatisfaction. Organizations that treat intelligent document processing as a core infrastructure investment, rather than a point solution, consistently report lower cost per decision and faster cycle times.
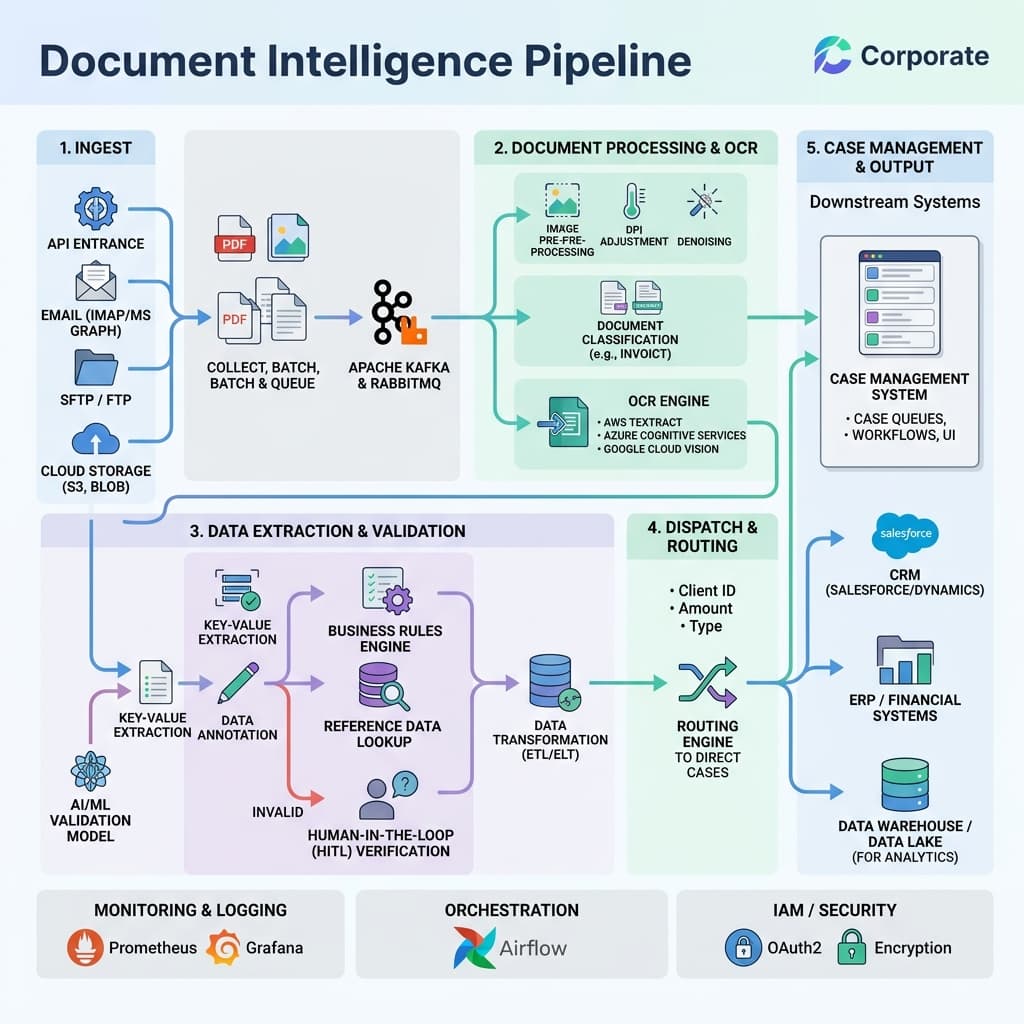
Ingestion layers must standardize file formats early without destroying native legal evidence. Compliance audits and fraud investigations occasionally require retrieving original analog artifacts months or years after initial submission. The safest pattern is to store immutable originals in durable object storage immediately upon receipt, then derive normalized copies for downstream machine learning pipelines. This separation protects chain of custody while keeping extraction workflows performant.
Optical character recognition remains the foundational step, but modern OCR extends well beyond simple text extraction. Layout aware models now preserve table structures, checkbox states, and spatial relationships between fields. For loan applications, preserving the positional context of a signature block relative to a disclosure paragraph matters legally. Claims intake similarly depends on correctly associating damage descriptions with policy section references embedded in multi-page PDF bundles.
We facilitate small-group sessions for customers and prospects without requiring a slide deck, focused on your stack, constraints, and the decisions you need to make next.
Model selection balances extraction accuracy, inference latency, and compute cost. High volume simple forms may use lightweight local extractors running on CPU infrastructure, while structurally complex commercial loan covenants require heavier foundation models coupled with ensemble logic. The cost per decision should remain transparent to business product owners so they can make informed trade-offs between speed and precision at the portfolio level.
Confidence scoring is the mechanism that separates reliable automation from reckless guessing. Every extracted field should carry a calibrated confidence value that reflects true posterior probability, not a raw softmax output. When confidence falls below a tuned threshold, the field routes to human review. Poorly calibrated scores either flood reviewers with unnecessary work or allow incorrect values to pass unchecked, both outcomes eroding trust in the entire pipeline.
Validation rules encode strict business logic directly inside the pipeline. Cross-field arithmetic checks, sequential date ordering, statutory regulatory caps, and format constraints must all execute deterministically. Machine learning proposes values; deterministic rules protect the system from accepting confident nonsense when training data drifts. This layered defense is especially critical for regulated loan disclosures where a single mismatched interest rate can trigger compliance violations.
Entity resolution adds another layer of intelligence by linking extracted names, addresses, and account numbers to existing records in core banking or policy administration systems. Fuzzy matching algorithms handle common variations like abbreviated street names or transposed digits in phone numbers. Successful entity resolution reduces duplicate case creation and accelerates straight-through processing by pre-populating downstream fields from known customer profiles.
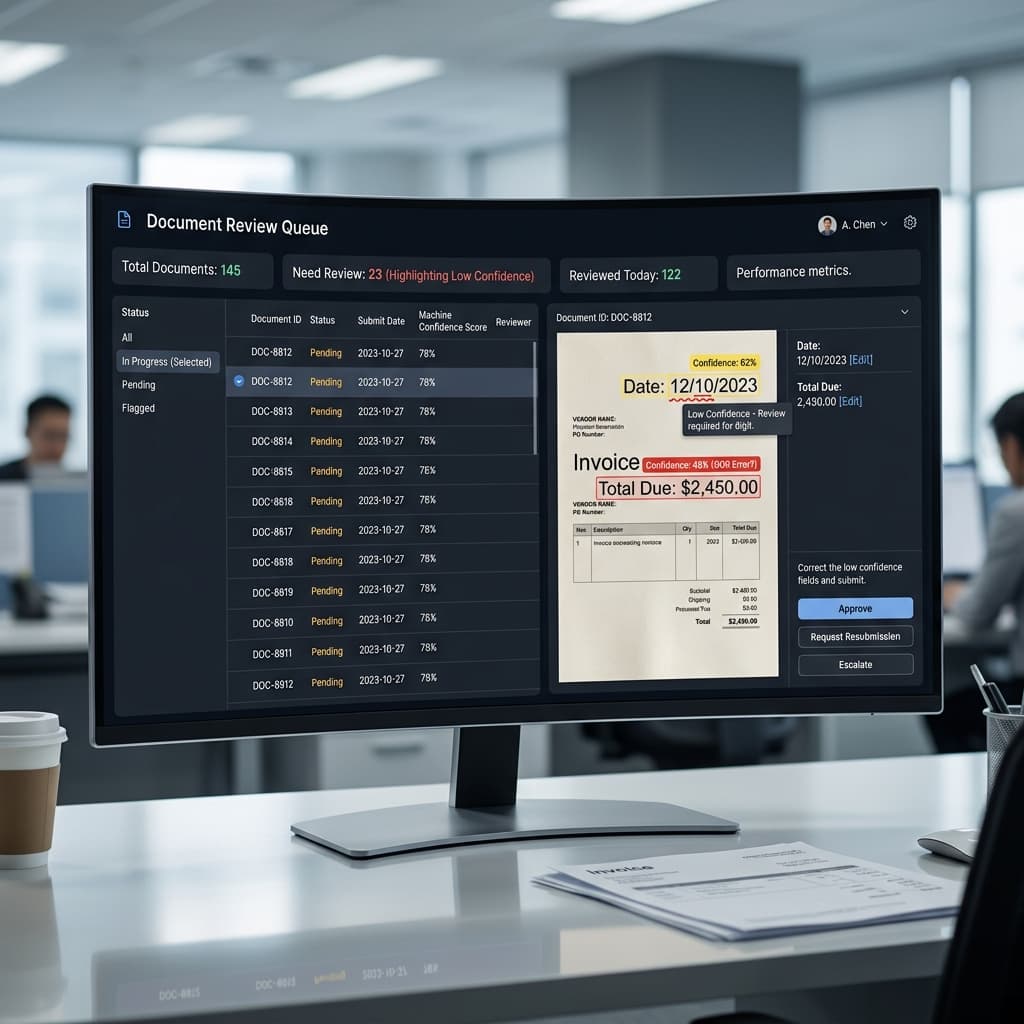
Human review queues require thoughtful software ergonomics to function at scale. Highlight low-confidence tokens in context, display original source bounding boxes alongside extracted text, and preload relevant customer account history. Reviewers should be able to accept, correct, or reject individual fields without navigating away from the current document. Throughput metrics should include reviewer fatigue indicators to prevent burnout-driven compliance errors during high volume periods.
Queue prioritization logic determines which cases surface first. Severity-weighted scoring that accounts for claim dollar amount, loan size, regulatory deadline proximity, and customer tier ensures that the most impactful reviews happen before lower-stakes corrections. Without intelligent prioritization, reviewers waste time on trivial exceptions while high-value cases age in the backlog, increasing both financial exposure and customer churn risk.
Continuous feedback loops close the model quality gap over time. When reviewers correct extraction errors, those labeled corrections should flow back into training pipelines under strict governance for personally identifiable information. Privacy anonymization techniques that strip too much semantic context will sabotage future model improvement cycles. The most effective teams maintain a curated golden dataset of corrected examples that serves as both a retraining source and a regression benchmark.
Version control for models and validation rules deserves the same rigor as application code. Every pipeline deployment should be traceable to a specific model checkpoint, rule configuration, and confidence threshold set. When extraction accuracy regresses after a model update, teams need the ability to roll back quickly without disrupting in-flight cases. Immutable deployment manifests and automated canary testing against held-out document samples are essential safeguards.
Security architecture intersects deeply with any external data intake pipeline. Malware scanning, content disarm and reconstruction, and least-privilege access controls on case storage repositories form the baseline. Exfiltration via fabricated loan applications is a recognized attack vector: adversaries submit documents containing embedded payloads designed to exploit downstream processing infrastructure. Defense in depth, including sandboxed extraction environments, mitigates this class of threat.
Audit trail completeness is non-negotiable in regulated industries. Every document transformation, model inference, human decision, and routing event should emit a structured log entry tied to a unique case identifier. When regulators or internal auditors request evidence that a specific loan disclosure was reviewed before approval, the system must produce a complete, tamper-evident chain of events without requiring engineering intervention.
Executive reporting should emphasize the true aggregate automation rate, categorize specific exception reasons, and visualize case decision time distributions. A flat accuracy percentage often hides financial pain in the long tail of messy unstructured documents. Dashboards that break down straight-through processing rates by document type, submission channel, and customer segment give operations leaders the granularity they need to target improvement investments effectively.
Integration patterns matter as much as extraction quality. Document intelligence pipelines rarely operate in isolation; they feed loan origination systems, claims adjudication platforms, and compliance case management tools. Designing clean, event-driven interfaces with well-defined schemas ensures that downstream consumers can evolve independently. Tightly coupled point-to-point integrations create fragile dependencies that amplify the blast radius of any single pipeline change.
Forward-looking architecture roadmaps must prepare for multilingual support, fluctuating mobile capture quality, and eventual vendor portability. Building enterprise document intelligence is a long journey where core architectural decisions should age gracefully. Teams that abstract model providers behind a common extraction interface today will find it far easier to adopt next-generation models tomorrow without rewriting validation logic or retraining human reviewers on new tooling.


