Insights · Article · Engineering · Apr 2026
Routing rules, synchronous options, session stickiness, and UX patterns when eventual consistency meets user expectations shaped by single-writer apps.

Read replicas are a cornerstone of horizontal database scaling, offloading read-heavy queries from the primary writer node and improving response times for geographically distributed users. However, asynchronous replication introduces an inherent delay between when data is committed on the primary and when it becomes visible on replicas. This gap, commonly called replication lag, creates stale read scenarios that can confuse users, corrupt downstream analytics, and undermine trust in your application.
Organizations adopt read replicas for compelling reasons. A single primary database under heavy mixed workloads will eventually saturate CPU, memory, or I/O capacity. Splitting read traffic to dedicated replicas can double or triple effective throughput without vertical scaling costs. Global deployments benefit from replicas positioned closer to regional users, dramatically reducing network round-trip latency. These advantages come with a consistency tradeoff that every architecture team must deliberately address before production deployment.
The core challenge is that most application frameworks and user interface patterns were designed under single-writer assumptions. When a user updates their profile, changes a billing address, or toggles a notification preference, they expect to see the new value immediately on the next page load. If a read replica has not yet received that write, the user sees outdated data. This mismatch between user expectation and system behavior is the root cause of nearly every stale read complaint.

Effective mitigation starts with precise measurement. Instrument each replica to expose current replication lag as a time-series metric, then compute percentile distributions rather than relying on simple averages. The p50 value tells you about typical conditions, but the p99 and p99.9 values reveal how bad lag gets during peak traffic, schema migrations, or long-running analytical queries that compete for replica resources.
We facilitate small-group sessions for customers and prospects without requiring a slide deck, focused on your stack, constraints, and the decisions you need to make next.
Averages mask dangerous outliers. A replica might report two milliseconds of average lag while occasionally spiking to fifteen seconds during batch processing windows. Those spikes are precisely when users are most likely to encounter stale reads, because high write volume on the primary and heavy processing on the replica co-occur. Alerting on tail latency percentiles gives your on-call engineers actionable signals well before users start filing support tickets.
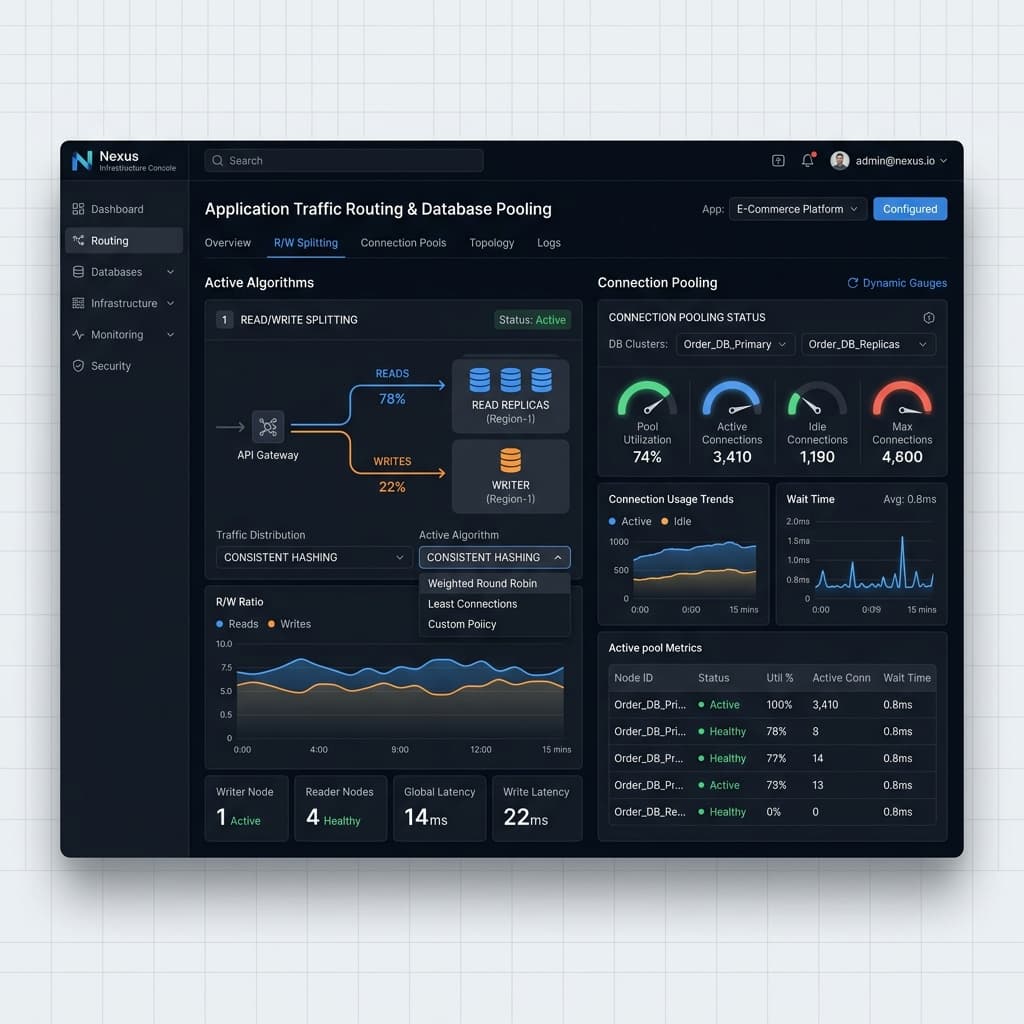
Several routing strategies exist to direct reads appropriately based on freshness requirements. The simplest approach is to route all reads immediately following a write back to the primary for a configurable grace period. More sophisticated systems use session stickiness, pinning a user connection to the primary for a brief window after any mutation. Read-your-writes tokens, supported natively by databases like CockroachDB and Amazon Aurora, let the client pass a logical timestamp that the replica must satisfy before returning results.
Choosing the right routing pattern depends on your team's operational maturity and your database's native capabilities. Session stickiness is straightforward to implement at the load balancer level but can create uneven replica utilization if a subset of users performs frequent writes. Token-based approaches distribute load more evenly but require application-level awareness of consistency tokens throughout your entire request lifecycle, including API gateways and every downstream backend service.
Caching layers introduce a second dimension of staleness that compounds replication lag. When a cache is populated from a lagging replica, the stale value persists in the cache until its time-to-live expires, potentially extending the window of inconsistency from milliseconds to minutes. This is especially problematic for session-scoped data, where a user's own actions appear to have no effect because the cache continues serving an outdated snapshot of their records.
To manage cache staleness, invalidate or refresh user-scoped cache keys immediately after any write operation that affects that user's data. Event-driven invalidation, where the write path publishes a cache-bust message to a topic or queue, is more reliable than relying on short TTL values alone. For shared reference data that changes infrequently, longer cache durations remain appropriate, but you should still maintain a mechanism to force a refresh during planned data migrations or bulk updates.
Synchronous replication eliminates stale reads entirely by requiring each replica to confirm receipt of every transaction before the primary acknowledges the commit to the client. The cost is significant: write latency increases proportionally to the network round trip between primary and replica, and a single slow or unreachable replica can stall all writes system-wide. This tradeoff makes synchronous replication impractical for most high-throughput, latency-sensitive applications.
Reserve synchronous replication for domains where regulatory or operational requirements demand zero tolerance for stale data. Financial ledger systems, healthcare record updates, and compliance audit trails are common examples. Even in these scenarios, consider semi-synchronous configurations that require acknowledgment from at least one replica rather than all replicas. This approach reduces the blast radius of a single replica failure while still providing stronger consistency than pure asynchronous replication.
Frontend patterns play a critical role in maintaining perceived consistency regardless of backend replication lag. Optimistic UI updates, where the client immediately reflects the user's action before receiving server confirmation, eliminate the most common stale read frustration. When the server eventually confirms the write, the UI state is already correct. If the write fails, the client can gracefully roll back and notify the user, which is statistically rare and far less disruptive than persistent perceived staleness.
Loading skeletons and progressive disclosure patterns further smooth the user experience during the brief window when replication is catching up. Instead of showing stale data, display a brief loading indicator for recently modified sections of the page. This approach honestly communicates that the system is processing rather than silently presenting outdated information. Users consistently report higher satisfaction with transparent loading states compared to interfaces that display silently incorrect data.
Operational recovery playbooks must cover the full spectrum of replica failure scenarios. Replica promotion to primary during an outage requires careful sequencing to avoid split-brain conditions where two nodes accept conflicting writes. Rebuilding a corrupted replica from a fresh snapshot can take hours for large datasets, during which remaining replicas absorb additional load. Documenting and regularly rehearsing these procedures ensures your team can execute them confidently under pressure rather than improvising during a severity-one incident.
Chaos engineering practices should specifically target replication infrastructure. Inject artificial network latency on replication links, pause replication entirely for controlled periods, and simulate replica crashes during peak traffic. These experiments validate that your monitoring detects lag spikes promptly, that your routing logic correctly falls back to the primary, and that your alerting pipelines page the right team before customers notice degraded consistency.
Cross-functional education is the final and often most neglected component of a sound replication strategy. Product managers who understand the consistency model can write feature specifications that explicitly state whether a workflow requires strong or eventual consistency. Designers can incorporate appropriate loading states into their mockups. When every discipline understands the tradeoffs between read replica lag and data freshness, the engineering team spends less time retrofitting consistency fixes into features that were designed without these constraints in mind.


